产品简介
产品概述
首云Kafka消息队列是基于原生Apache Kafka构建的一个分布式、高吞吐量、可分区、多副本的消息系统,广泛用于日志收集与存储、构建事件中心、监控数据聚合、流式数据处理等大数据领域,为其提供良好的功能支撑。
首云Kafka消息队列基于发布/订阅模式,提供在线伸缩、监控、manager嵌入工具等功能,和超高性能的配置,能帮助您更高效、简单地管理集群。利用云管平台,您能够轻松构建并运行生产应用程序,而无需进行预置和管理服务器、详细规划扩展事件以支持负载变化等基础设施管理,这意味着您可以花费较更多的时间来构建应用程序。
云管功能
首云Kafka消息队列不仅具备kafka消息中间件的特性,还具备很多云平台的管理功能,能够为客户大幅度减低运维成本,提升运维响应速度和运维质量,功能包括:
产品优势
开箱即用
100% 兼容开源社区 Kafka(0.10.0.0 及以上版本),全面兼容 Kafka 开源客户端
提供第三方管理工具,集成Kafka manager控制台,可对集群、节点等进行高级管理操作。
基于现有的开源 Apache Kafka 生态的代码,无需改造,即可无缝使用
安全与加密
-
数据安全
-
集群可提供隔离的VDC,您可以自主控制网络配置;同时VD可以通过公网IP和带宽设置连接到您的Kafka Service(创建时选择)
-
数据流加密
-
通过代理网络之间以及您的集群上的客户端与代理网络之间的 TLS 在传输过程中加密数据。
-
支持基于 TLS 的证书身份验证和 Apache Kafka 访问控制列表 (ACL),用于对集群内的创建器和使用器进行身份验证和授权。
监控告警
弹性扩展
丰富的性能选择
产品功能
l 托管
只需要在首云控制台中单击几下,就可以创建托管的Apache Kafka集群。
l KafkaManger集成
通过提供开箱即用的原生Kafka Manager开源服务,使您能够更轻松地管理和监控Apache Kafka集群,提供对Topic、Partitions的可视化管理。
l 监控和警报
首云Kafka Service提供核心链路运行时巡检,集群健康扫描,实例、消息堆积等多维度监控与告警设置。
l 数据安全
其他您自己的配置,集群可提供隔离的VDC,您可以自主控制网络配置;同时VD可以通过公网IP和带宽设置连接到您的Kafka Service(创建时选择)。
技术原理
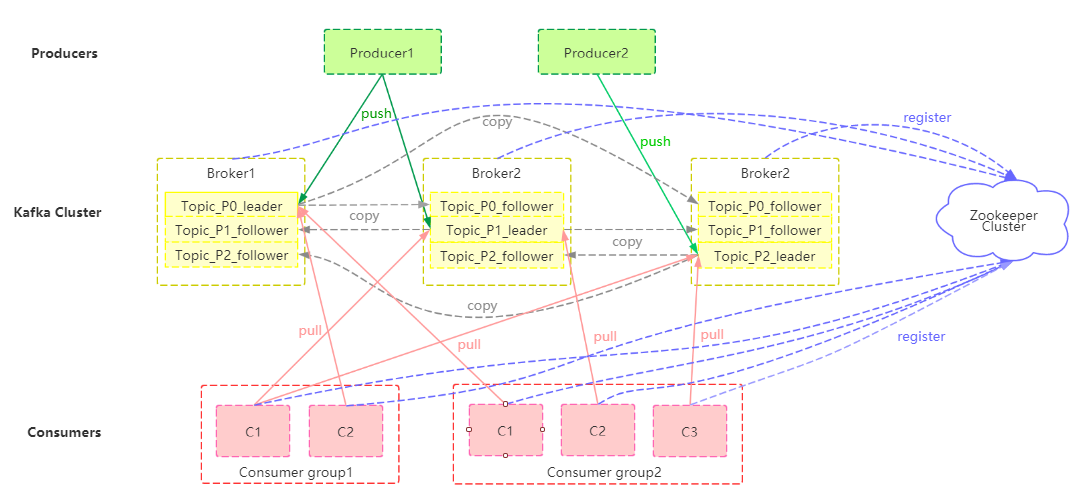
三副本状态下首云Kafka消息队列的产品架构图如下所示:
其中:
Producer:可以是多种来源的多种信息,通过 push 模式向首云 Kafka 消息队列的Broker集群发送消息。
Broker:用于存储消息的服务器,一个节点对应一个broker。Kafka Broker 支持水平扩展, Kafka Broker 节点的数量越多,Kafka 集群的吞吐率越高。
Topic:Kafka对消息进行归类,发送到集群的每一条消息都要指定topic。每个Broker可以存储多个Topic。
Partition:每个Topic包含一个或多个分区,每个partition内部存储的数据都是有序的。一个Partition将以一个Broker作为Leader进行读写等操作,同时按照选取的备份数和备份机制备份至其他Broker中。
Consumer:通过 pull 模式从首云 Kafka 消息队列的Broker 订阅并消费消息。
Consumer group:每个Consumer属于一个特定的Consumer group,每个Consumer group消费同一个Topic;一条消息可以发送到不同的consumer group,但一个Consumer group中只能有一个Consumer能消费这条消息。
Zookeeper:协调管理集群的配置、选举 leader 分区,并且在 Consumer Group 发生变化时,进行负载均衡。当leader所在的Broker挂掉之后,通过选举机制从followers中重新选取leader。
主要配置:
消息保留时间:1-2160小时;
Topic分区:1-100;
Topic副本:双副本或三副本;
网络类型:私网。
应用场景
网站活动跟踪
成功的网站运营都会非常关注站点的用户行为并进行分析。通过消息队列 Kafka ,您可以实时收集网站活动数据(包括用户浏览页面、搜索及其他行为等),并通过“发布/订阅”模型实现:
能够实现:
-
高吞吐:网站所有用户产生的行为信息庞大,需要吞吐量来支持;
-
弹性扩容:网站活动导致行为数据激增,云平台可以快速按需扩容;
-
大数据分析:可对接 Storm/Spark 实时流计算引擎,亦可对接 Hadoop/ODPS 等离线数据仓库系统。
日志聚合
许多公司,典型如电商平台每天都会产生大量的日志(一般为流式数据,如搜索引擎 pv、查询等),相较于日志为中心的系统,比如 Scribe 或者 Flume 来说,消息队列 Kafka 在提供同样高效的性能时,可以实现更强的数据持久化以及更低的端到端响应时间。消息队列 Kafka 的这种特性决定它非常适合作为日志收集中心:
-
消息队列 Kafka 忽略掉文件的细节,可以将多台主机或应用的日志数据抽象成一个个日志或事件的消息流,异步发送到消息队列 Kafka 版集群,从而做到低的 RT(响应时间);
-
消息队列 Kafka 客户端可批量提交消息和压缩消息,对生产者而言几乎感觉不到性能的开支;
-
消费者可以使用 Hadoop、ODPS 等离线仓库存储和 Strom、Spark 等实时在线分析系统对日志进行统计分析。
能够实现:
-
应用与分析解耦:构建应用系统和分析系统的桥梁,并将它们之间的关联解耦;
-
高可扩展性:具有高可扩展性,即当数据量增加时可通过增加节点快速水平扩展;
-
在线/离线分析系统:支持实时在线分析系统和类似于 Hadoop 的离线分析系统。
流计算处理
在很多领域,如股市走向分析、气象数据测控、网站用户行为分析,由于数据产生快、实时性强且量大,您很难统一采集这些数据并将其入库存储后再做处理,这便导致传统的数据处理架构不能满足需求。
与传统架构不同,消息队列 Kafka 以及 Storm/Samza/Spark 等流计算引擎的出现,就是为了更好地解决这类数据在处理过程中遇到的问题,流计算模型能实现在数据流动的过程中对数据进行实时地捕捉和处理,并根据业务需求进行计算分析,最终把结果保存或者分发给需要的组件。
能够实现:
-
流动的数据:构建应用系统和分析系统的桥梁,并将它们之间的关联解耦;
-
高可扩展性:由于数据产生快且数据量大,需要高可扩展性;
-
流计算引擎:可对接开源 Storm/Samza/Spark等。
数据中转枢纽
近 10 多年来,诸如 KV 存储(HBase)、搜索(ElasticSearch)、流式处理(Storm/Spark Streaming/Samza)、时序数据库(OpenTSDB)等专用系统应运而生。这些系统是因为单一的目标而产生,也因其简单性使得在商业硬件上构建分布式系统变得更加容易且性价比更高。
通常,同一份数据集需要被注入到多个专用系统内。例如,当应用日志用于离线日志分析,搜索单个日志记录同样不可或缺,而构建各自独立的工作流来采集每种类型的数据再导入到各自的专用系统显然不切实际,利用消息队列 Kafka 版作为数据中转枢纽,同份数据可以被导入到不同专用系统中。
能够实现:
-
高容量存储:能在商业硬件上存储高容量的数据,实现可横向扩展的分布式系统;
-
一对多消费模型:“发布/订阅”模型,支持同份数据集能同时被消费多次;
-
同时支持实时和批处理:支持本地数据持久化和 Page Cache,在无性能损耗的情况下能同时传送消息到实时和批处理的消费者。
用户指南
Kafka集群创建
(1)用户登录系统,在左侧列表页点击“大数据服务”——“Kafka消息队列”进入Kafka集群列表界面。
点击页面右上方的【新建集群】开始进行Kafka集群创建。
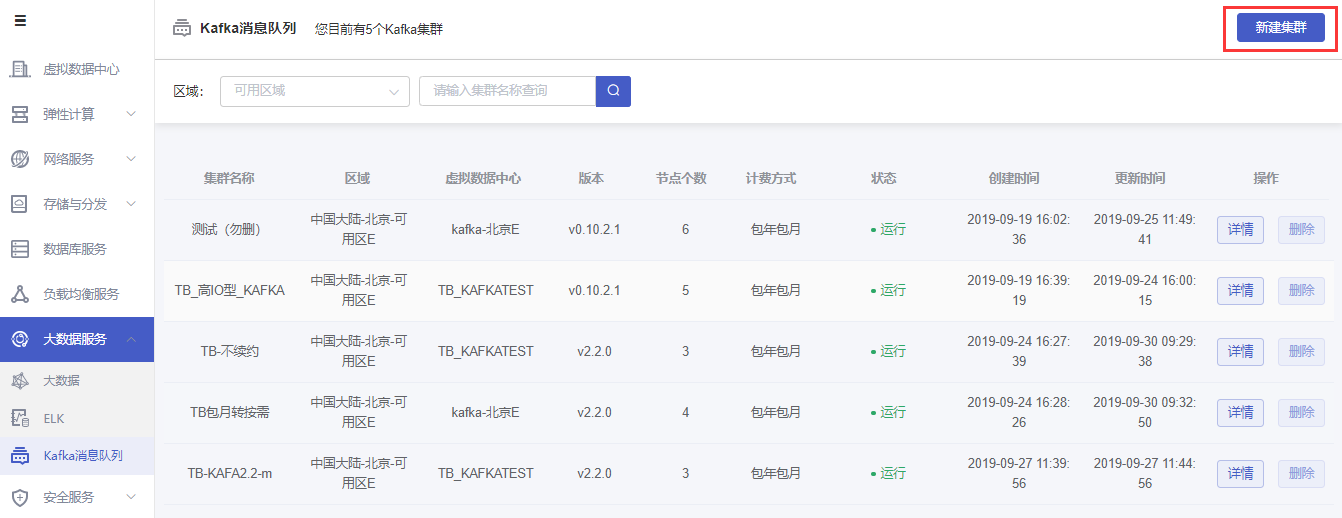
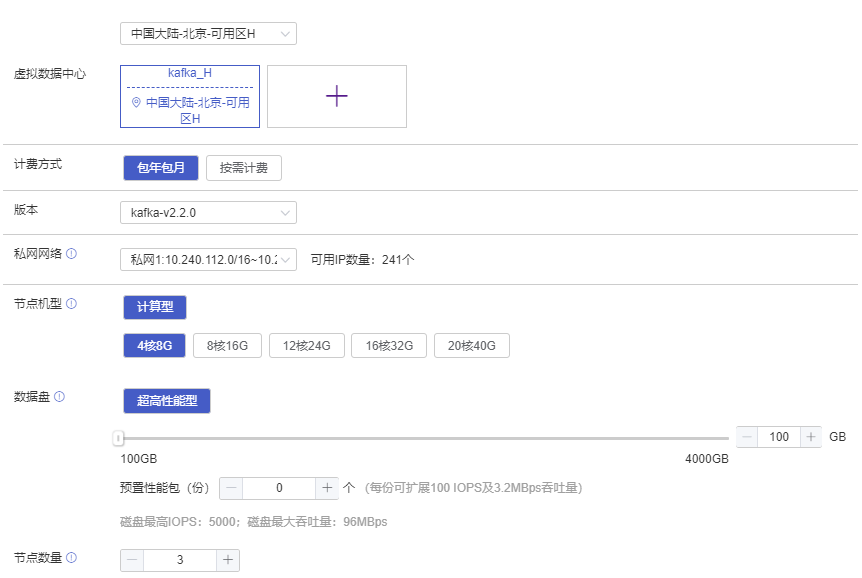
(2)进入Kafka集群创建界面后用户可以根据需求选取配置如图所示:
虚拟数据中心:选择可创建Kafka集群的虚拟数据中心,可以根据区域进行筛选选择。
计费方式:选择Kafka集群的计费方式:包年包月、按需计费。
版本:选择Kafka服务的版本:kafka-v0.10.2.1、kafka-v2.2.0。
私网网络:选择Kafka服务节点的通讯私网网络,默认占用所选VDC的私有网络IP地址。
节点机型:选择Kafka集群下节点的机型及计算配置。可选的机型有“高性能型”、“高IO型”。
数据盘:选择每个节点对应的数据盘。可选数据盘类型有性能型、超高性能型(SSD)云硬盘,超高性能型云硬盘(SSD)还可通过购买预置性能包提高IOPS及吞吐量。
节点数量:选择创建Kafka集群时要购买的kafka节点数量,节点数量最低为3台(默认前3台用于master、调度、备份,不支持删除此3台默认节点)
集群名称:设置Kafka集群的名称,最多支持输入36个字符。
消息保留时长:设置Kafka集群的消息保留的时间,默认保留24个小时,支持保留1-2160个小时。
配置及计费信息:当用户创建Kafka集群时可在创建界面右侧查看已选配置及计费,如下图所示
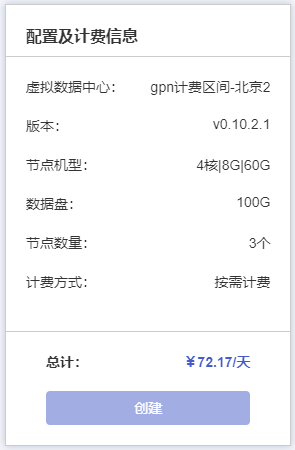
点击配置及计费窗口底部的【创建】按钮创建Kafka集群。
Kafka集群管理
已创建的Kafka集群可进行节点、topic、Consumer Group、登录控制台管理。
在Kafka集群列表页面,选择某一集群,点击操作列的【详情】按钮,进入管理页面。
1 详情
详情页面可查看Kafka的集群信息,并可进行更改集群名称、变更包年包月计费的续约配置、修改消息保留时长操作。
1.1 修改集群名称
(1)在“集群详情”页面-基本信息模块中点击“集群名称”后的【编辑】按钮。
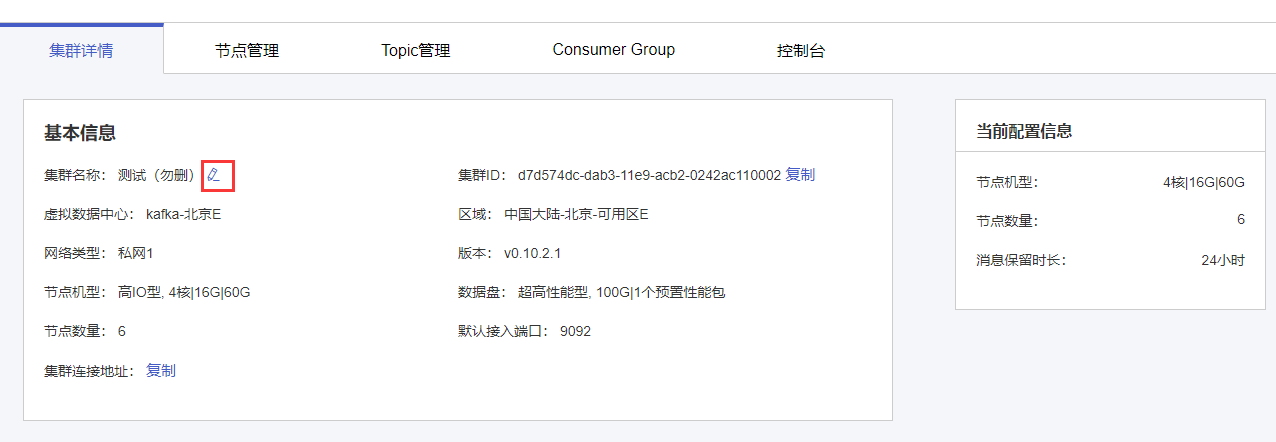
(2)在出现的编辑框中输入最新集群名称,可在“变更配置及计费信息”框中确认变更内容,点击【保存】按钮,完成更改。
1.2 调整自动续约
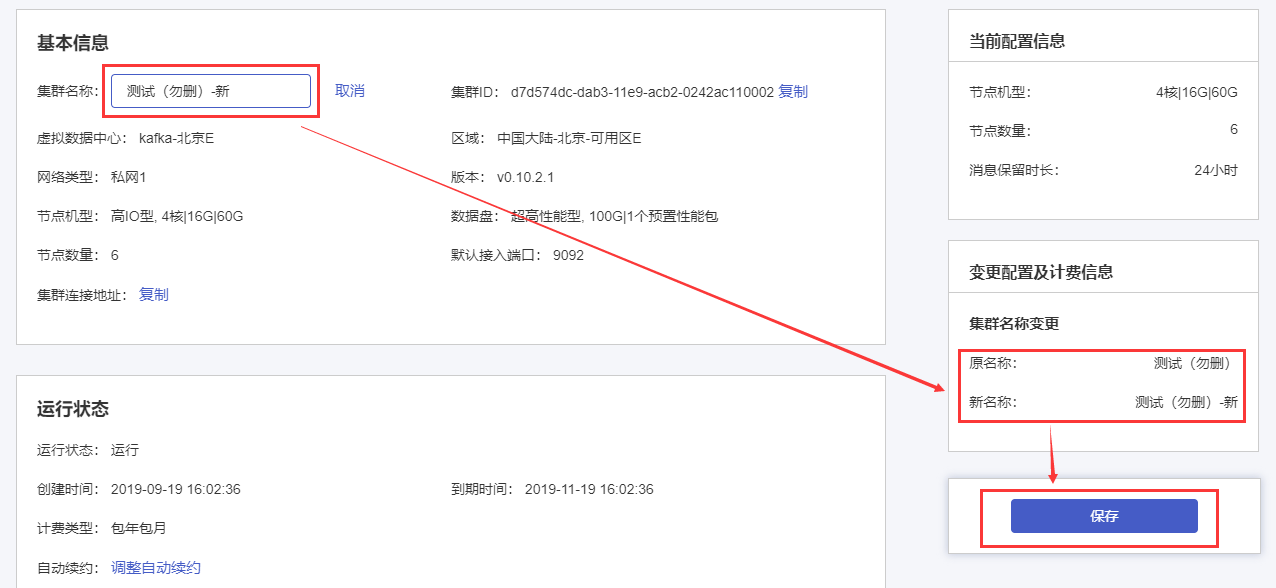
(1)点击“运行状态”模块中的【调整自动续约】按钮,选择续约配置:
a. 关闭:关闭自动续约。Kafka集群到期以后不自动续费,集群到期后将被回收;
b. 开启:开启自动续约。Kafka集群到期后系统自动扣费进行续约;
1)开启-包年包月:继续按照包年包月进行续约,可选择每次续约的周期(续至月底/自然月)
2)开启-按需:当Kafka集群到期后将转为按需计费
(2)在右侧“变更配置及计费信息”模块中确认变更内容无误,点击【保存】按钮,完成变更。
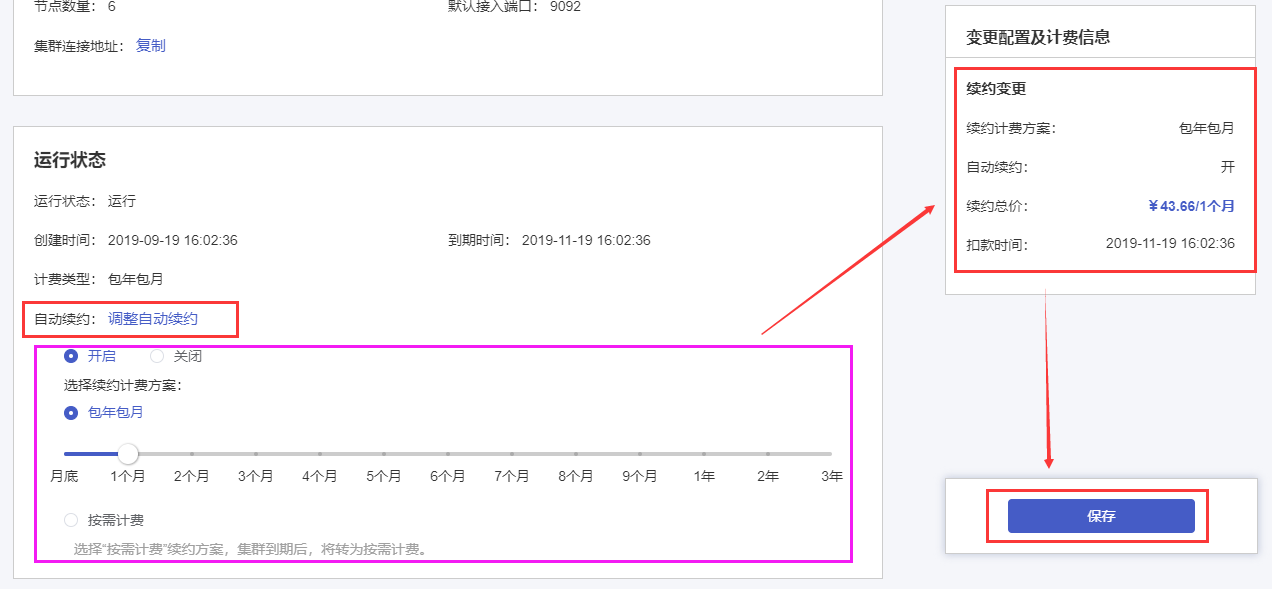
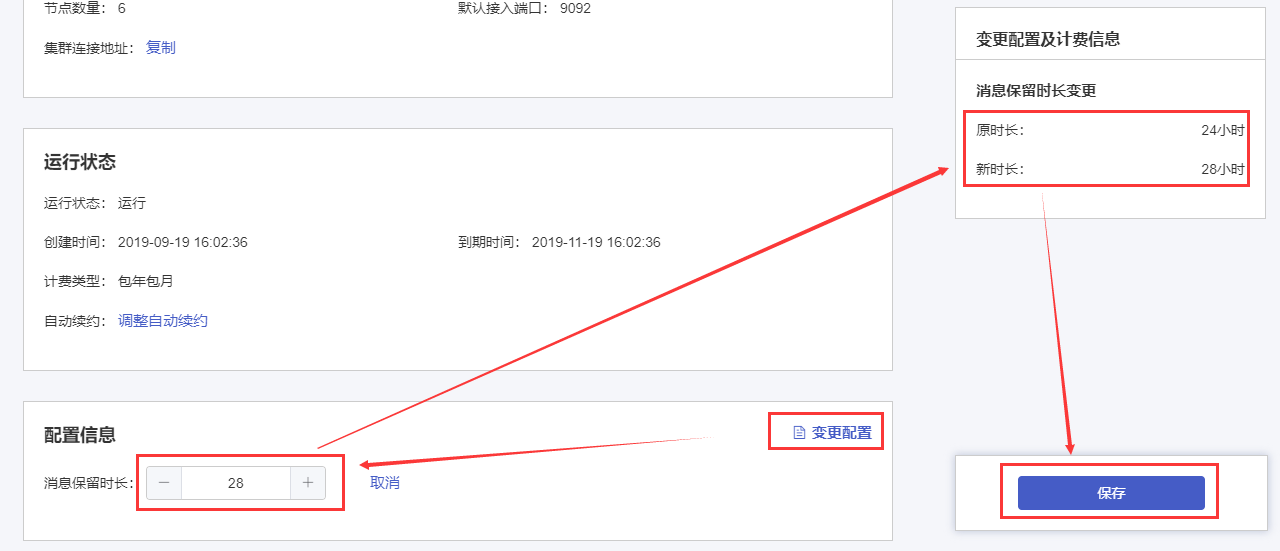
1.3 修改消息保留时长
点击“配置信息”模块右上角的【变更配置】按钮。调整消息保留时间,在“变更配置及计费信息”框中确认变更内容无误,点击【保存】按钮,完成变更。
2 节点管理
节点管理页面可查看Kafka的集群的节点,并可进行添加节点、删除节点操作。
2.1 添加节点
(1)在节点管理页面,点击左上方【添加节点】按钮。
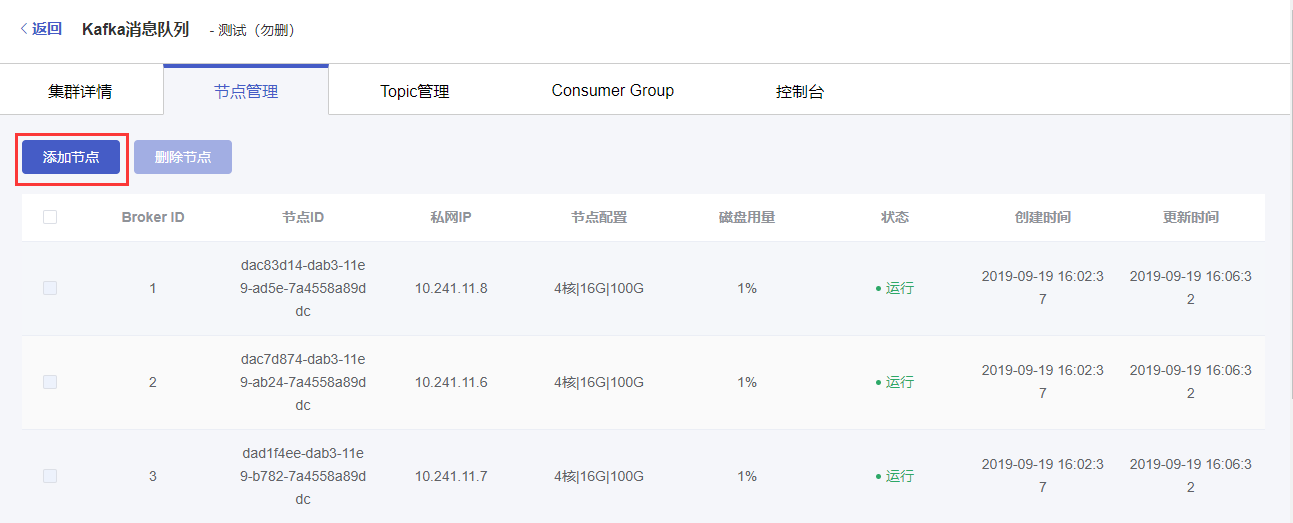
(2)在添加节点弹窗中,选择要添加的节点数量,确认价格,点击【确定】进行节点创建。
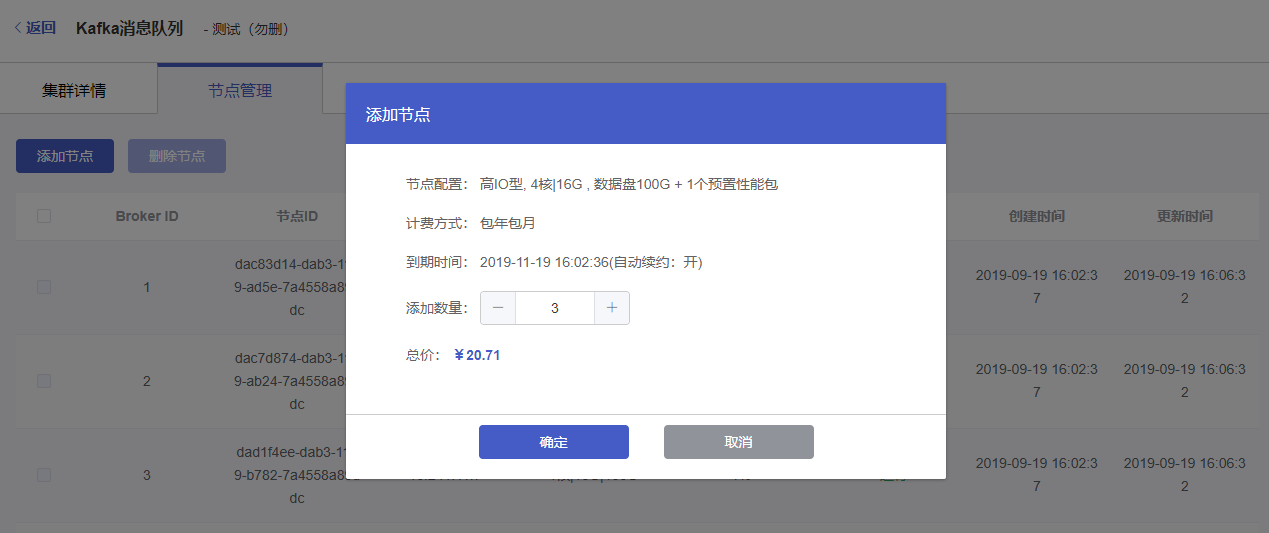
说明:添加的节点配置与创建Kafka集群时所选的配置一致,暂不支持指定单节点配置进行创建。
2.2 删除节点
勾选要删除的节点左侧的选框,点击页面上方的【删除节点】按钮。
在弹出的删除确认弹窗中点击【确认】按钮,进行节点删除。
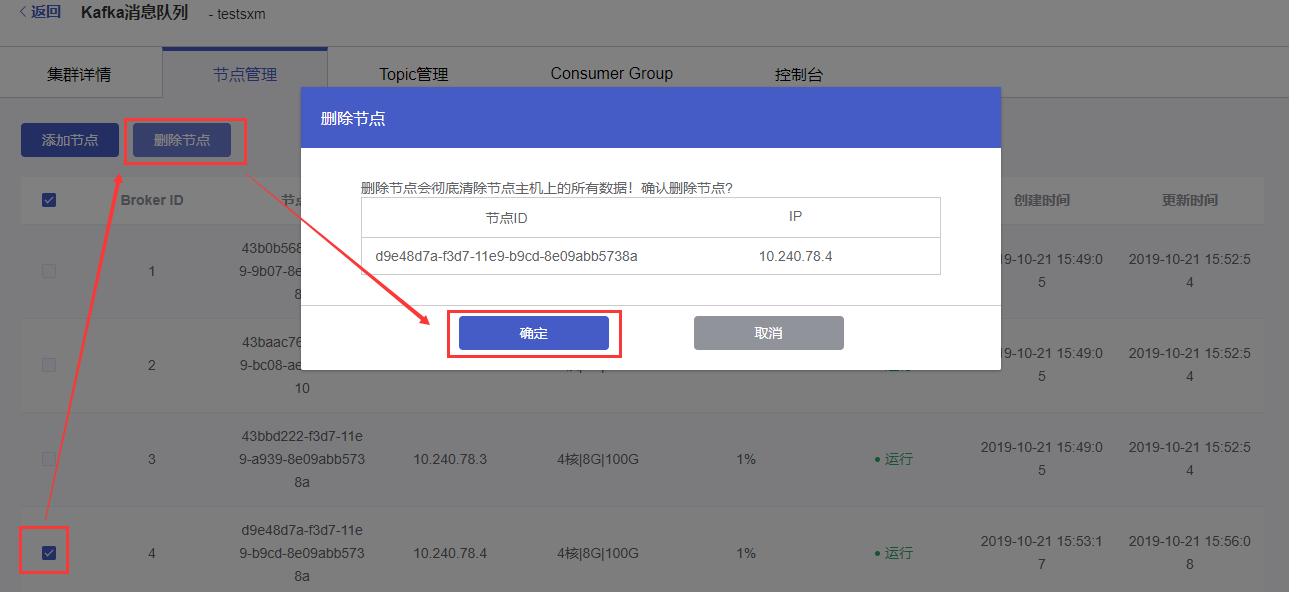
说明:
1. 默认Kafka集群有3个节点用于master、调度、备份,不支持删除;
2. 包年包月计费的kafka集群节点不支持删除;
3 Topic管理
节点管理页面可查看Kafka的集群的topic,并可进行新建topic、删除topic操作。
3.1 Topic创建
点击页面右上方【新建Topic】按钮,在弹出的窗口中填写和选择topic信息:
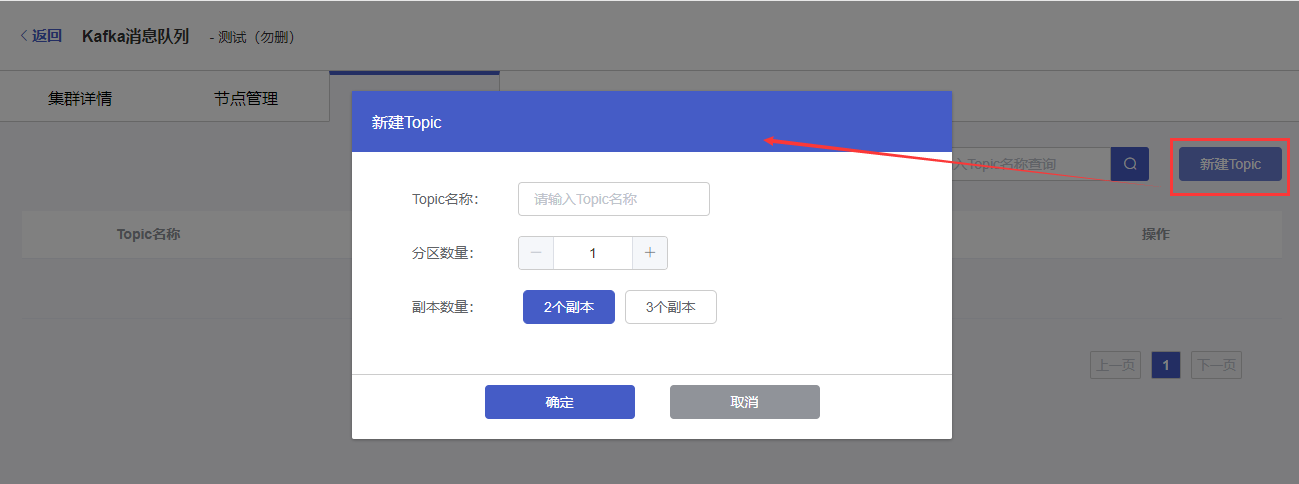
Topic名称:设置topic的名称。支持输入字母/数字/下划线/./-,不可超过36个字符。
分区数量:选择topic的分区数量,支持1-100个分区。
副本数量:选择副本数量,支持2个/3个副本。
点击【确定】按钮,创建Topic。
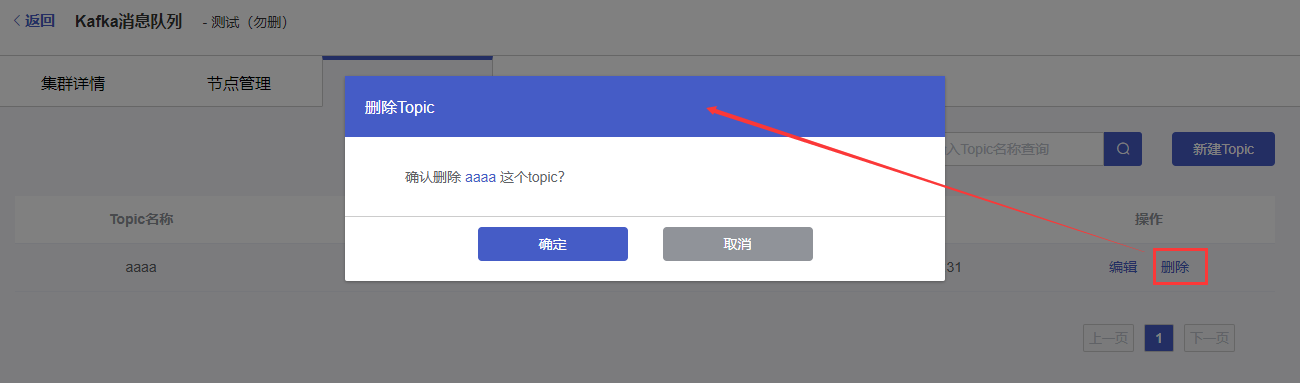
3.2 Topic删除
选择要删除Topic右侧操作列的【删除】按钮,在删除确认弹窗中点击【确定】按钮,删除topic。
4 Consumer Group管理
Consumer Group管理页面可查看消费组列表、消费组的分区状态,并可进行offset重置操作。
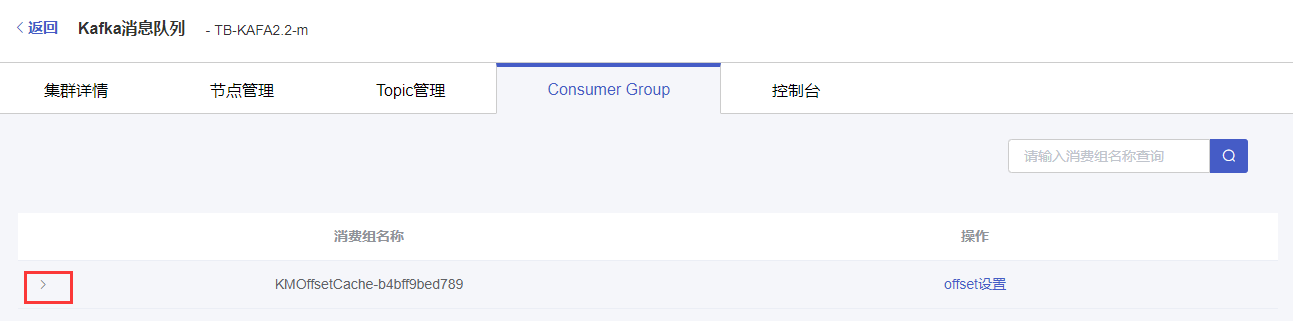
4.1 查看分区状态
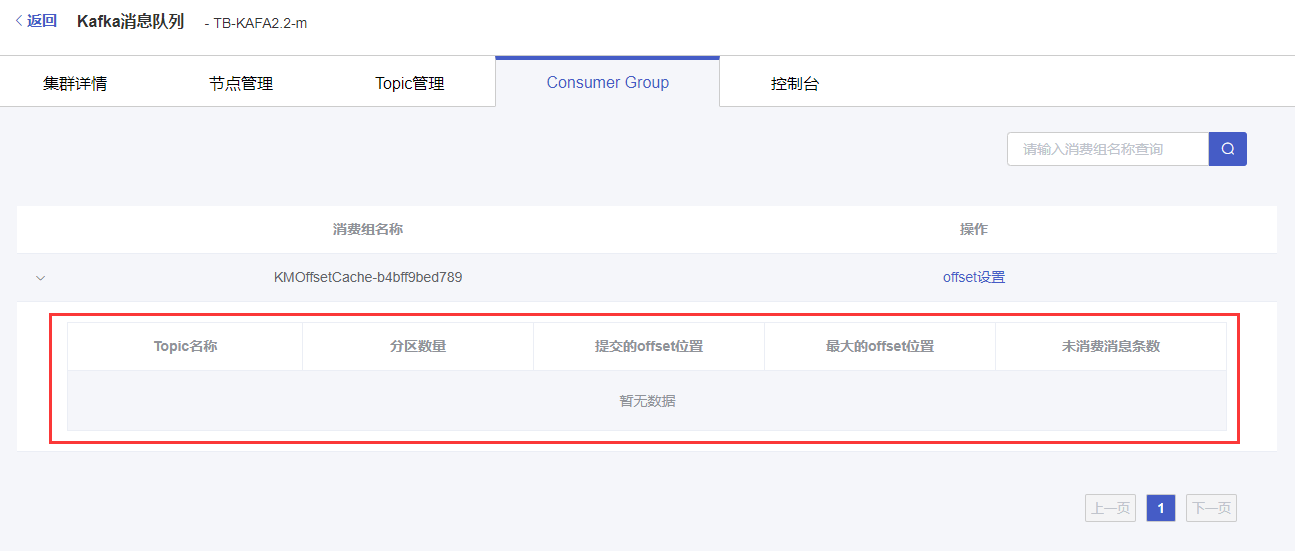
(1)在Consumer Group页面点击消费组左侧的“展开”按钮,可以展开分区状态信息。
(2)在展开的分区状态内容,可查看对应topic的分区数量、提交的offset位置、最大的offset位置、未消费消息条数。
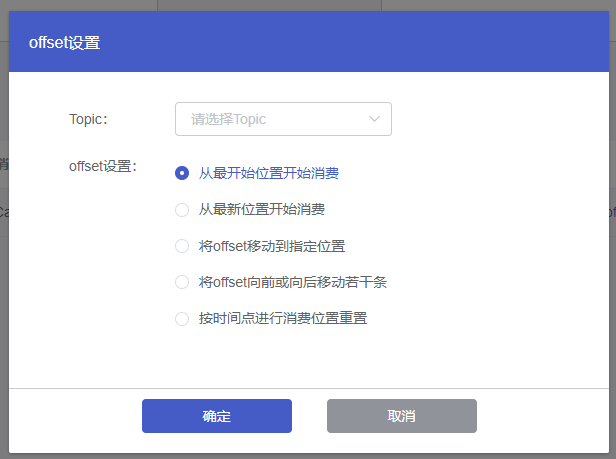
4.2 offset设置
(1)选择对应消费组操作列的【offset设置】按钮
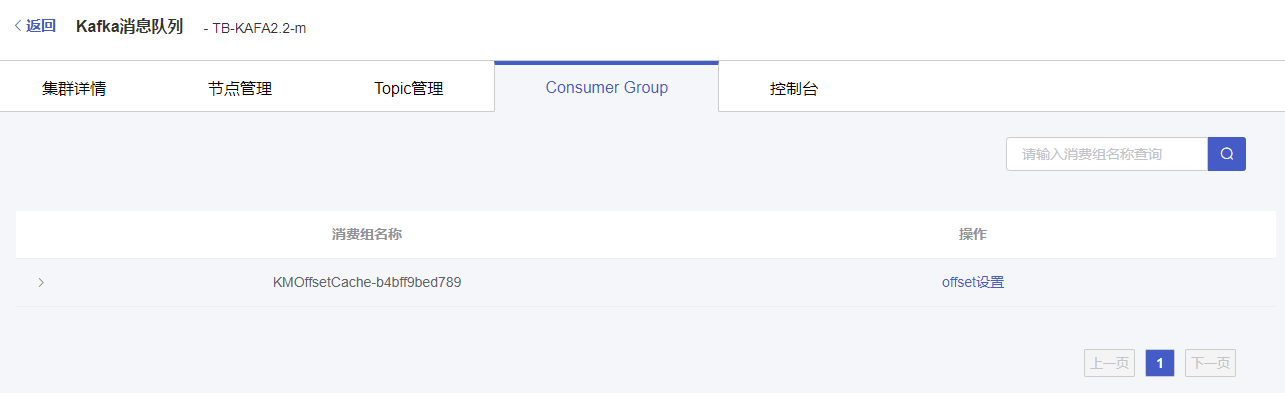
(2)在弹窗中选择topic、offset位置,点击【确定】,完成offset设置操作。
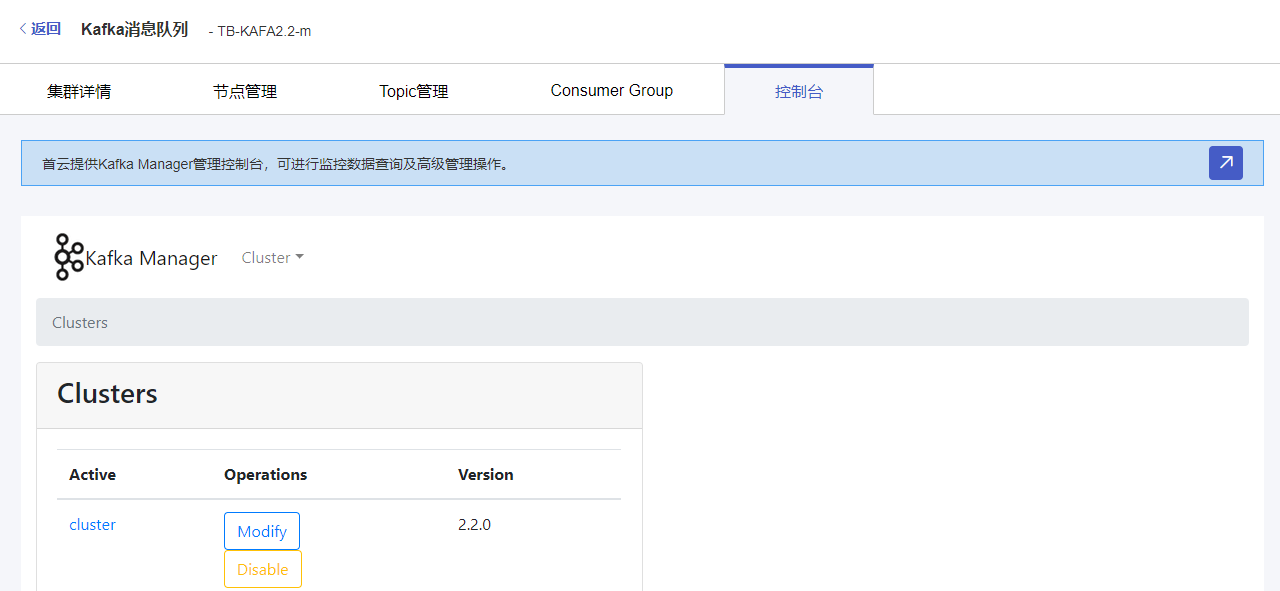
5 控制台
控制台是首云提供的Kafka Manager工具,用于辅助管理Kafka集群,可进行监控数据查询、高级管理操作。
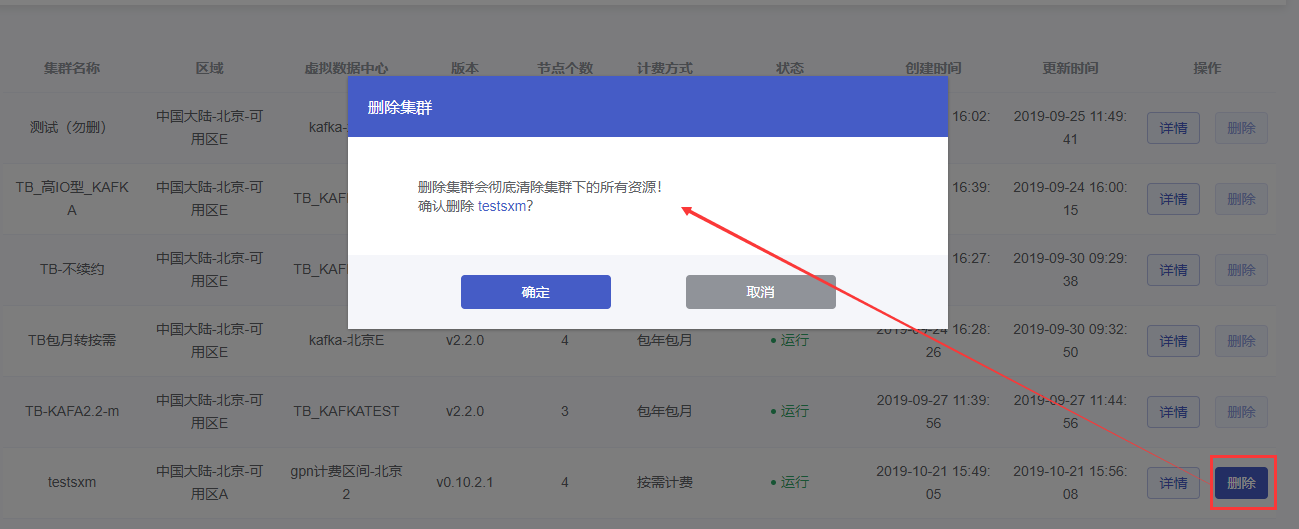
Kafka集群删除
点击要删除Kafka集群操作列的【删除】按钮,在弹出的删除确认弹窗中,点击【确定】按钮,完成删除集群操作。
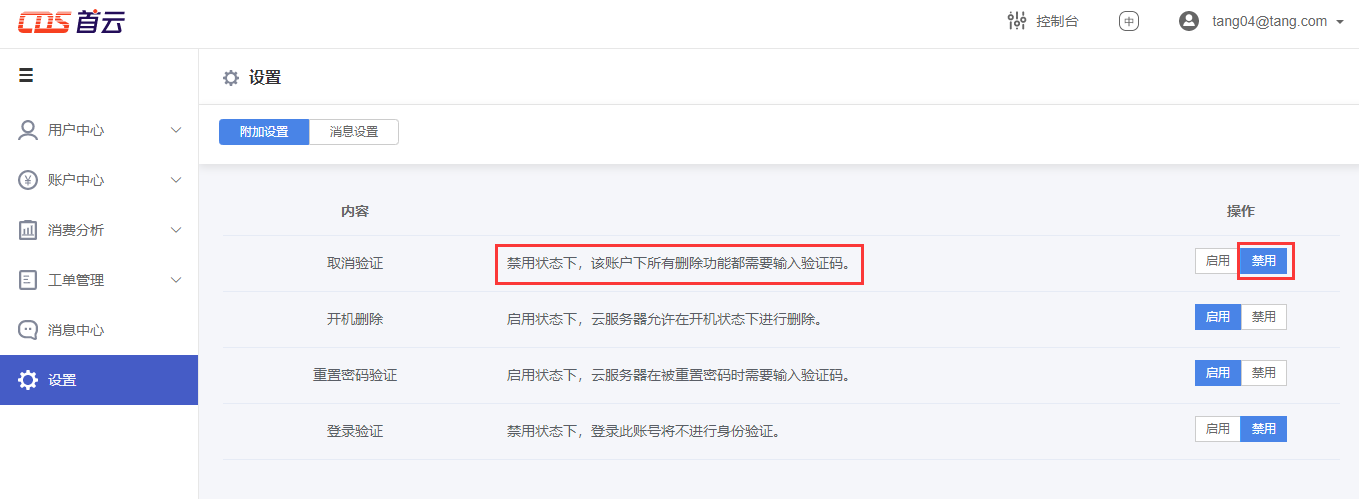
注意:删除集群会清除其下所有资源,风险较大,建议您开启资源删除验证,在删除Kafka集群时,会进行身份验证,完成验证后才可成功执行集群删除任务。
如何开启资源删除验证?
用户中心——设置——附加设置,取消验证的操作设置为【禁用】状态,则删除资源时将进行身份验证才可删除。
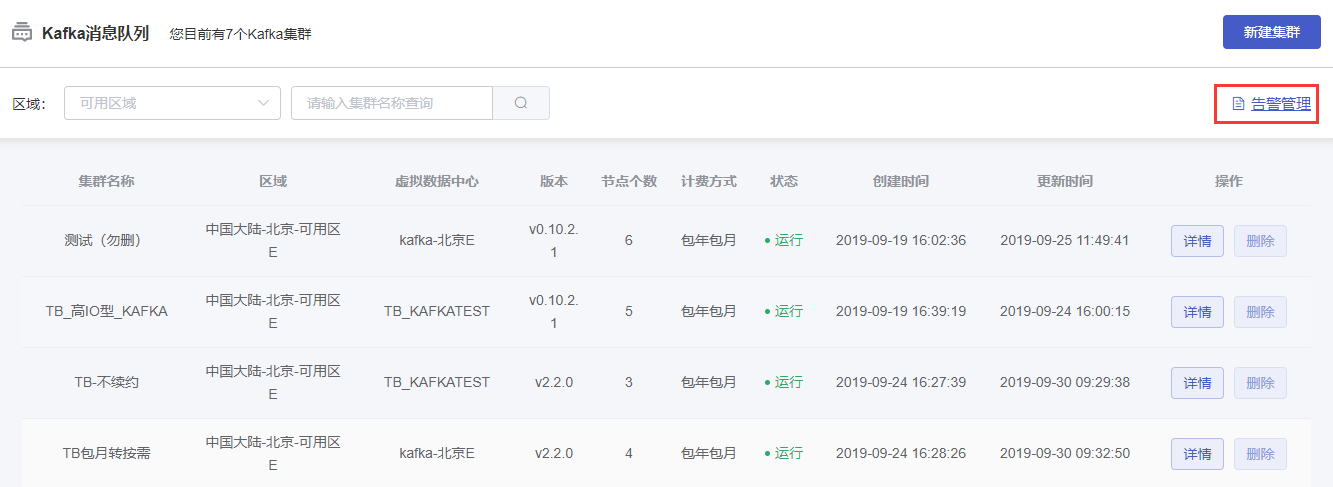
告警管理
可对已创建的Kafka集群设置告警策略。
在Kafka消息队列集群列表页面,点击页面右上方的【告警管理】按钮,进入告警管理页面。
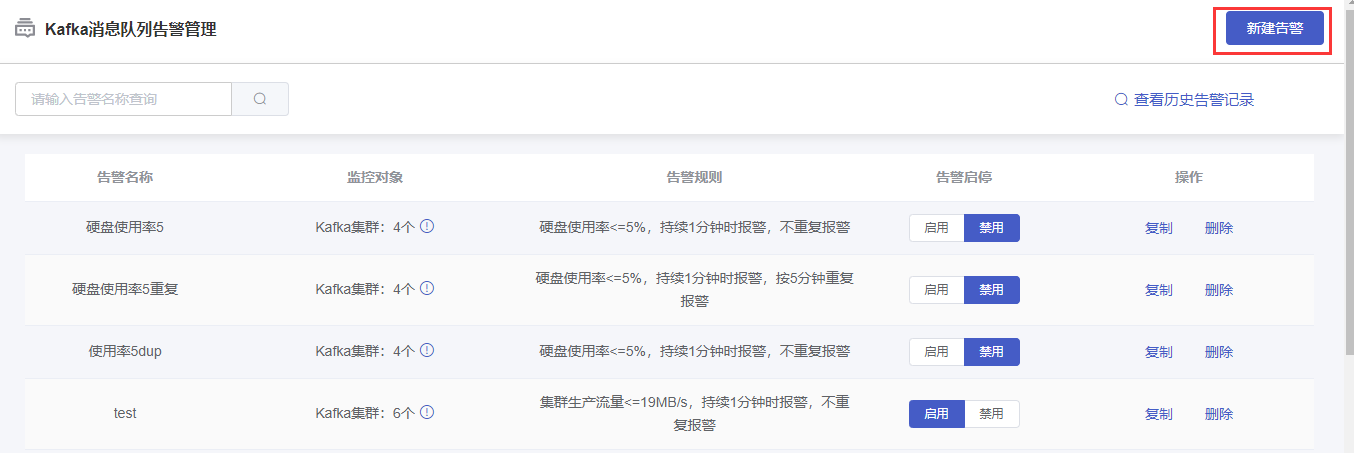
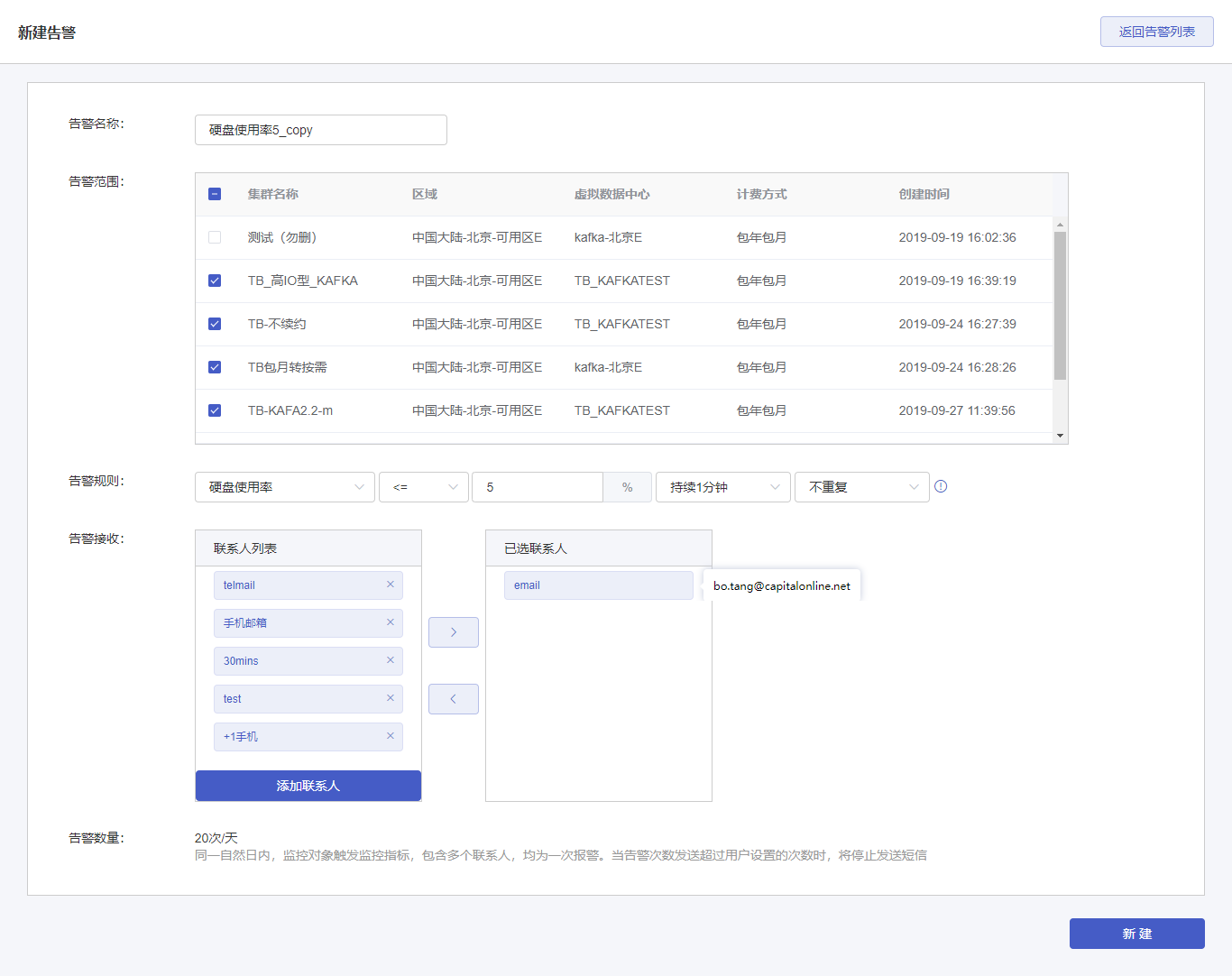
1 新建告警
(1)在“Kafka消息队列告警管理”页面,点击右上方【新建告警】按钮,进入告警创建页面。
(2)在新建告警页面,填写告警内容,如下图所示:
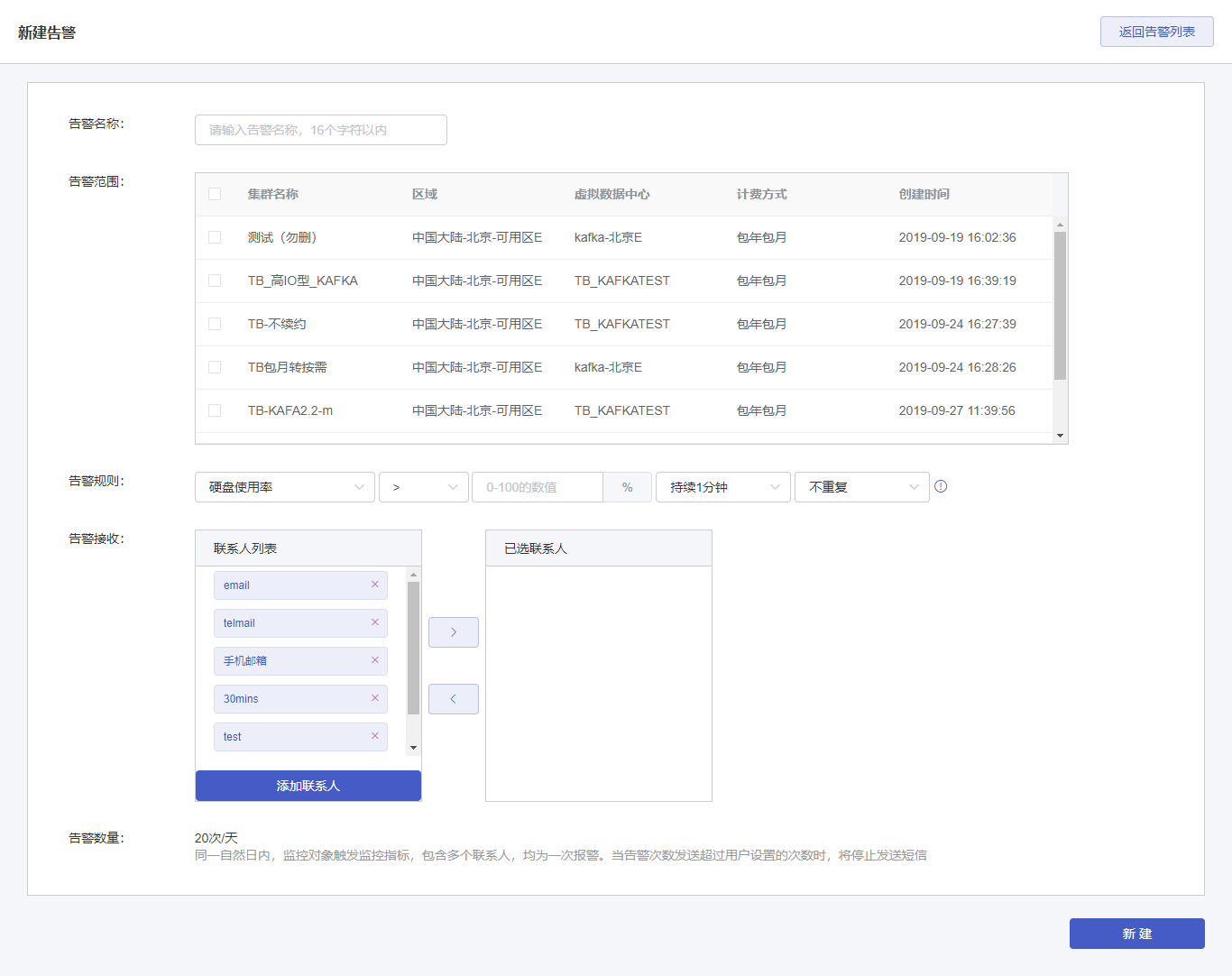
告警名称:告警策略的名称,32个字符以内。
告警范围:选择此告警监控的Kafka集群。
告警规则:设置触发告警的条件及告警通知规则,支持的告警类型有生产流量、消费流量、磁盘使用率。
告警接收:选择此告警的接收人。左侧联系人列表显示所有已有的联系人,可选择作为此告警的接收人。在“联系人列表”中点击某个联系人,将会移到右侧“已选联系人”,变成此告警的接收人。
添加联系人:创建新的联系人。需输入联系人姓名、手机号码、邮箱地址。
告警数量:邮件告警没有数量限制,短信告警有数量限制。同一自然日诶,当触发监控指标,会同时给多个联系人发送告警,视为1次报警,当报警次数达到20次,短信告警达到上线,不在进行短信方式告警通知,邮件正常告警。
点击【创建】按钮,成功创建告警。
2 告警管理
在“Kafka消息队列告警管理”页面,可对已创建的告警策略进行基本管理操作。
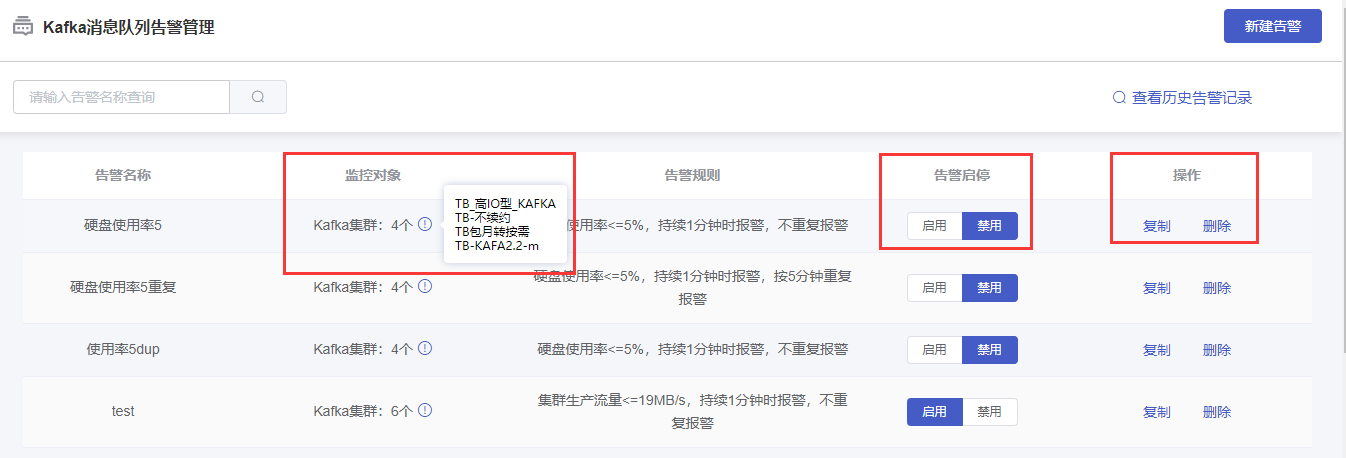
2.1 查看列表
在列表区域可查看告警名称、监控对象、告警规则、告警状态等信息。
2.2 告警启停
新创建的告警策略,默认为“禁用”状态,可在“告警启停”列,进行【启用】或【禁用】操作。
2.3 复制
复制是基于当前告警策略,在创建告警时继承对应的告警内容(告警名称、告警范围、告警规则、告警接收人)。用于快速创建相似告警策略。
(1)选择某一告警策略,点击“操作”列的【复制】按钮,进入“新建告警”页面。

(2)在新建告警页面会发现,已经继承了对应的告警内容。在此基础上进行修改后,点击【新建】按钮,可快速创建一个新的告警。
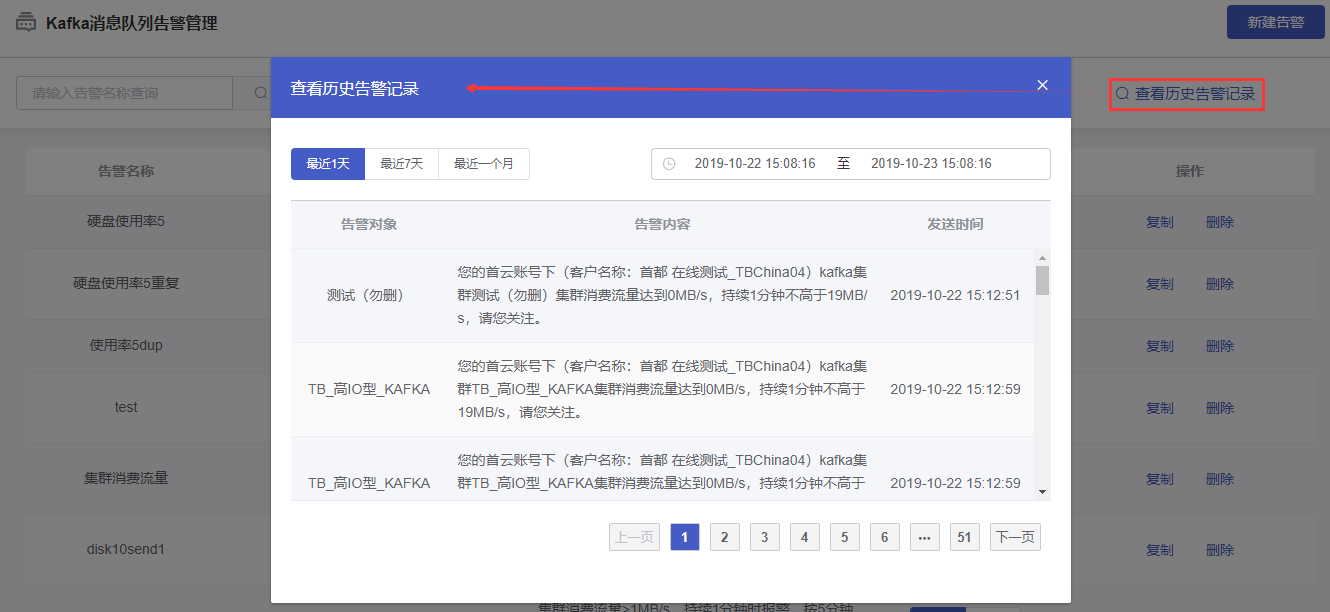
2.4 查看历史告警
点击“Kafka消息队列告警管理”右上方【查看历史告警记录】按钮,在出现的弹窗中,可按时间查询此客户的kafka告警历史。包含信息:告警对象(Kafka集群名称)、告警内容、发送时间。
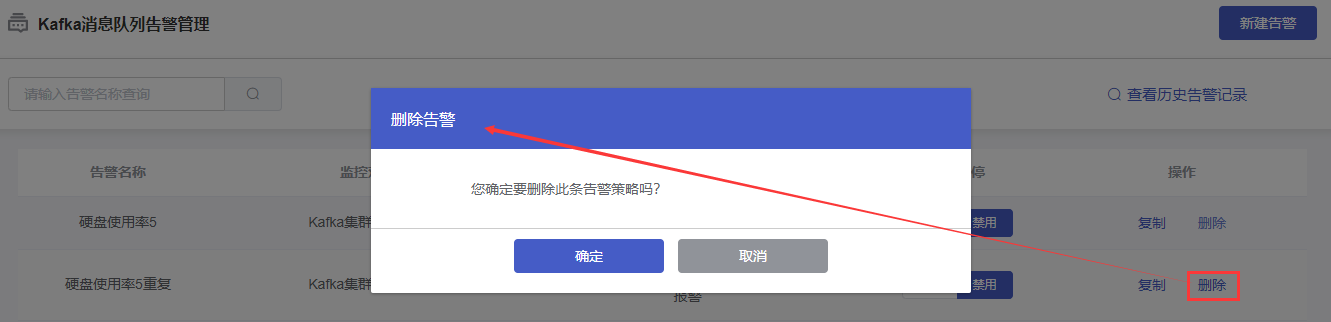
3 告警删除
在“Kafka消息队列告警管理”页面的列表中,选择某一告警策略,在“操作”列中,点击【删除】按钮。在弹出的“删除告警”确认页面中,点击【确认】按钮,完成删除。
SSL客户端适配
首云kafka支持通过SSL加密和认证,并且可以通过该方式使集群具有出公网的能力。 开通方式: 在首云控制台创建kafka集群时,选择公网实例,并且选择绑定客户公网ip,则默认打开SSL安全认证;在集群详情的数据安全栏可以看到公网连接的地址和加密认证文件下载按钮
kafka自带客户端
1,在页面下载SSL证书kafka.truststore和 kafka.keystore 放置到客户端某一目录下,此处为/usr/local/ssl_store/
[root@kafka-cds kafka]# ls /usr/local/ssl_store/
kafka.keystore kafka.truststore
2,创建客户端配置文件client_ssl.properties
[root@kafka-cds kafka]# cat client_ssl.properties
# 这里是SSL连接地址,使用的是9093端口
bootstrap.servers=......kafka.yun-paas.com.:9093
# 使用的是SSL协议
security.protocol=SSL
# truststore证书路径
ssl.truststore.location=/usr/local/ssl_store/kafka.truststore
# truststore密码:统一为kafkasslpwd
ssl.truststore.password=kafkasslpwd
# keystore证书路径
ssl.keystore.location=/usr/local/ssl_store/kafka.keystore
# keystore密码:统一为kafkasslpwd
ssl.keystore.password=kafkasslpwd
# 为了兼容kafka v2.0+
ssl.endpoint.identification.algorithm=
3,生产者客户端命令,配置文件为client_ssl.properties:
[root@kafka-cds kafka]# bin/kafka-console-producer.sh --broker-list ......kafka.yun-paas.com.:9093 --topic ssltest --producer.config ./client_ssl.properties
4,消费者客户端命令,配置文件为client_ssl.properties(与生产者的配置文件相同):
[root@kafka-cds kafka]# bin/kafka-console-consumer.sh --bootstrap-server ......kafka.yun-paas.com.:9093 --topic ssltest --consumer.config ./client_ssl.properties
Java客戶端
1, 导入maven包
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.0.1</version>
</dependency>
2, 导入依赖并创建Properties
import org.apache.kafka.clients.CommonClientConfigs;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.config.SslConfigs;
Properties props = new Properties();
# 这里是SSL连接地址,使用的是9093端口
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "......kafka.yun-paas.com.:9093");
# 使用的是SSL协议
props.put(CommonClientConfigs.SECURITY_PROTOCOL_CONFIG, "SSL");
# truststore证书路径
props.put(SslConfigs.SSL_TRUSTSTORE_LOCATION_CONFIG, "/usr/local/ssl_store/kafka.truststore");
# truststore密码:统一为kafkasslpwd
props.put(SslConfigs.SSL_TRUSTSTORE_PASSWORD_CONFIG, "kafkasslpwd");
# keystore证书路径
props.put(SslConfigs.SSL_KEYSTORE_LOCATION_CONFIG,
"/usr/local/ssl_store/kafka.keystore");
# keystore密码:统一为kafkasslpwd
props.put(SslConfigs.SSL_KEYSTORE_PASSWORD_CONFIG, "kafkasslpwd");
# 为了兼容kafka v2.0+
props.put(SslConfigs.SSL_ENDPOINT_IDENTIFICATION_ALGORITHM_DOC, "");
python 客户端
参考: http://maximilianchrist.com/python/databases/2016/08/13/connect-to-apache-kafka-from-python-using-ssl.html
选用pykafka库,安装方法:
pip install pykafka
1,从kafka公网实例详情页面下载kafka.keystore 文件,上传到客户端服务器上。
2,提取密钥
-
2.1 配置完Apache Kafka实例后,您将拥有两个JKS容器:“ kafka.keystore”和“ kafka.truststore”。第一个包含已签名的客户端证书,其私钥和用于对其进行签名的“ CARoot”证书。第二个证书包含用于签署客户端证书和密钥的证书。因此,我们需要的所有内容都包含在“ kafka.client.keystore.jks”文件中。要获得其内容的概述 , 可以查看:
keytool -list -rfc -keystore kafka.keystore
keytool -exportcert -alias cds-cluster -keystore \
kafka.keystore -rfc -file certificate.pem
-
2.3 接下来,我们将提取客户密钥。并不直接支持此功能keytool,这就是为什么我们必须首先将密钥库转换为pkcs12格式,然后从中提取私钥: 第二条命令仅将密钥输出到STDOUT。从那里可以将其复制并粘贴到“ key.pem”中。确保复制在“ -BEGIN PRIVATE KEY”-和“ -END PRIVATE KEY”-之间的所有行。
keytool -v -importkeystore -srckeystore kafka.keystore \
-srcalias cds-cluster -destkeystore cert_and_key.p12 -deststoretype PKCS12
openssl pkcs12 -in cert_and_key.p12 -nocerts -nodes
keytool -exportcert -alias CARoot -keystore kafka.client.keystore.jks -rfc \
-file CARoot.pem
此时,证书文件kafka.keystore所在路径下会有3个文件:CARoot.pem,key.pem, certificate.pem
3,配置python客户端:
from pykafka import KafkaClient, SslConfig
import logginglogging.basicConfig(level=logging.DEBUG)
config = SslConfig(
# 分别配置3个密钥文件的路径
cafile="/root/CARoot.pem",
certfile='/root/certificate.pem',
keyfile='/root/key.pem',
# 密码默认都是kafkasslpwd
password=b"kafkasslpwd"
)
# 集群详情页面的SSL连接地址
hosts = "......kafka.yun-paas.com.:9093,......yun-paas.com.:9093"
# 配置client, broker_version 试版本而定
client=KafkaClient(hosts=hosts,
ssl_config=config,
broker_version='2.2.0')
topic = client.topics["ssltest"]
# Write hello world to ssltest topicwith
topic.get_sync_producer() as producer:
producer.produce(b'Hello pykafka ssl')
# Print all messages from ssltest
topicconsumer = topic.get_simple_consumer()
for message in consumer:
if message is not None:
print('{} {}'.format(message.offset, message.value))
备注: consumer 消费时需要安装python-snappy;
pip3 install python-snappy
会出现很多依赖问题:
1,找不到snappy.h
下载源码 snappy-1.1.3.tar.gz
解压,编译
tar -zxvf snappy-1.1.3.tar.gz
cd snappy-1.1.3
./configure
make && make install
2,找不到Python.h
yum search python | grep -i devel
yum install python36-devel.x86_64
Flume 接入kafka公网(SSL加密)
请选择apache-flume-1.8.0-bin 版本 1,下载apache-flume-1.8.0-bin.tar.gz文件,解压为 apache-flume-1.8.0-bin 2,进入apache-flume-1.8.0-bin目录,在conf目录下新建kafka.conf 文件
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /tmp/logs
a1.sources.r1.fileHeader = true
# Describe the sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = ssltest
# 页面SSL连接地址
a1.sinks.k1.kafka.bootstrap.servers = ......-11ea.kafka.yun-paas.com.:9093...
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.k1.kafka.producer.compression.type = snappy
a1.sinks.k1.kafka.producer.security.protocol = SSL
# kafka.truststore证书的路径
a1.sinks.k1.kafka.producer.ssl.truststore.location = /tmp/ssl/kafka.truststore
# kafka.truststore证书的密码,统一为kafkasslpwd
a1.sinks.k1.kafka.producer.ssl.truststore.password = kafkasslpwd
# kafka.keystore证书的路径
a1.sinks.k1.kafka.producer.ssl.keystore.location = /tmp/ssl/kafka.keystore
# kafka.keystore证书的密码,统一为kafkasslpwd
a1.sinks.k1.kafka.producer.ssl.keystore.password = kafkasslpwd
a1.sinks.k1.kafka.producer.ssl.endpoint.identification.algorithm=
a1.sinks.k1.kafka.producer.ssl.key.password=kafkasslpwd
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
购买指南
购买方式
当您想要使用首云Kafka消息队列时,您可以按照以下步骤购买服务:
1.登录/注册CDS首云控制台;
2.点击左侧菜单列表:大数据服务>Kafka消息队列,选择“新建集群”,建立您的Kafka集群;
3.在“新建集群”页面,选择您希望配备的性能和设备,并为您的Kafka集群命名;
4.勾选完毕后,您可以看到当前设置下的价钱详情。单击“创建”并完成付款,即刻便可以开始使用Kafka消息队列服务。
计费说明
首云Kafka消息队列支持包年包月、按需计费两种计费方式,收费项包括节点机型和节点存储,节点存储包括数据盘和预置性能包两个项目。根据您所选择的产品规格,有不同的定价。而消息保留时长、Topic数量及分区数量、备份、监控告警等服务项均不再收取额外费用。
不同虚拟数据中心下,相同规格的服务器等能提供的性能不同,单价也有所不同;但相同虚拟数据中心下,计费单价仅受到市场影响。
定价实例
包年包月模式下某用户购买服务后的计费方法为:
某用户选择数据中心为中国大陆-北京-H,BJ-A,计费方式为包年包月,节点机型从4核8G升配为8核16G,数据盘容量由100GB升配为300GB,预置性能包选购3个,节点数量4个,那么该用户需要支付的价钱计算为:
节点机型8核16G:634.4元/个/月;
数据盘300GB:100元/100GB/月*300GB=300元/月;
预置性能包3个:4元/个/月*3个=12元/月;
节点数量:4个;
总费用计算为:(634.4+300+12)*4=3785.6元/月。
产品定价
首云Kafka消息队列收费项包括节点机型和节点存储,节点存储包括数据盘和预置性能包两个项目。部分节点机型不支持用户额外购买预置性能包。
包年包月
|
地域 |
流量规格 |
按需标价 |
包年包月价格 |
|
大区 |
可用区 |
计费规格 |
按需价格
(元/天)
|
按需价格
(元/小时)
|
包月价格
(元/月)
|
包年价格
(元/年)
|
|
亚太地区 |
新加坡-可用区D
新加坡-可用区A
新加坡-可用区B
新加坡-可用区C
东京-可用区A
首尔-可用区A
中国香港-可用区A
中国台北-可用区A
|
4C8G |
131.75 |
5.49 |
3589.78 |
43077.30 |
|
4C16G |
137.79 |
5.74 |
3754.47 |
45053.62 |
|
8C16G |
180.48 |
7.52 |
4917.50 |
59010.00 |
|
8C32G |
187.20 |
7.80 |
5100.49 |
61205.91 |
|
10C24G |
202.14 |
8.42 |
5507.60 |
66091.20 |
|
10C48G |
226.39 |
9.43 |
6168.51 |
74022.14 |
|
16C32G |
234.62 |
9.78 |
6392.75 |
76713.00 |
|
16C64G |
255.68 |
10.65 |
6966.56 |
83598.74 |
|
32C128G |
511.37 |
21.31 |
13933.12 |
167197.49 |
|
性能型磁盘1G |
0.02 |
0.0007 |
0.41 |
4.90 |
|
硬盘(SSD)1G |
0.05 |
0.0020 |
1.16 |
13.92 |
|
亚太地区 |
印度-可用区A
印度-可用区B
|
4C8G |
120.89 |
5.04 |
3293.40 |
39520.74 |
|
4C16G |
126.43 |
5.27 |
3444.49 |
41333.89 |
|
8C16G |
165.60 |
6.90 |
4511.50 |
54138.00 |
|
8C32G |
171.76 |
7.16 |
4679.38 |
56152.61 |
|
10C24G |
185.47 |
7.73 |
5052.88 |
60634.56 |
|
10C48G |
207.73 |
8.66 |
5659.23 |
67910.71 |
|
16C32G |
215.28 |
8.97 |
5864.95 |
70379.40 |
|
16C64G |
234.60 |
9.78 |
6391.39 |
76696.64 |
|
32C128G |
469.21 |
19.55 |
12782.77 |
153393.28 |
|
性能型磁盘1G |
0.02 |
0.0007 |
0.38 |
4.51 |
|
硬盘(SSD)1G |
0.04 |
0.0018 |
1.06 |
12.77 |
|
美洲地区 |
达拉斯-可用区A
达拉斯-可用区B
达拉斯-可用区C
达拉斯-可用区G
达拉斯-可用区I
达拉斯-可用区J
洛杉矶-可用区A
纽约-可用区A
弗吉尼亚-可用区A
迈阿密-可用区A
|
4C8G |
131.75 |
5.49 |
3589.78 |
43077.30 |
|
4C16G |
137.79 |
5.74 |
3754.47 |
45053.62 |
|
8C16G |
180.48 |
7.52 |
4917.50 |
59010.00 |
|
8C32G |
187.20 |
7.80 |
5100.49 |
61205.91 |
|
10C24G |
202.14 |
8.42 |
5507.60 |
66091.20 |
|
10C48G |
226.39 |
9.43 |
6168.51 |
74022.14 |
|
16C32G |
234.62 |
9.78 |
6392.75 |
76713.00 |
|
16C64G |
255.68 |
10.65 |
6966.56 |
83598.74 |
|
32C128G |
511.37 |
21.31 |
13933.12 |
167197.49 |
|
性能型磁盘1G |
0.02 |
0.0007 |
0.41 |
4.90 |
|
硬盘(SSD)1G |
0.05 |
0.0020 |
1.16 |
13.92 |
|
中国大陆 |
北京-可用区A
北京-可用区B
北京-可用区C
北京-可用区E
北京-可用区H
上海-可用区A
上海-可用区C
无锡-可用区A
广州-可用区A
|
4C8G |
91.28 |
3.80 |
2472.51 |
29670.12 |
|
4C16G |
95.47 |
3.98 |
2585.94 |
31031.34 |
|
8C16G |
125.04 |
5.21 |
3387.00 |
40644.00 |
|
8C32G |
129.69 |
5.40 |
3513.04 |
42156.46 |
|
10C24G |
140.04 |
5.84 |
3793.44 |
45521.28 |
|
10C48G |
156.85 |
6.54 |
4248.65 |
50983.83 |
|
16C32G |
162.55 |
6.77 |
4403.10 |
52837.20 |
|
16C64G |
177.14 |
7.38 |
4798.32 |
57579.86 |
|
32C128G |
354.29 |
14.76 |
9596.64 |
115159.71 |
|
性能型磁盘1G |
0.01 |
0.0005 |
0.28 |
3.36 |
|
硬盘(SSD)1G |
0.03 |
0.0014 |
0.80 |
9.60 |
|
欧洲地区 |
法兰克福-可用区A
法兰克福-可用区B
阿姆斯特丹-可用区A
|
4C8G |
131.75 |
5.49 |
3589.78 |
43077.30 |
|
4C16G |
137.79 |
5.74 |
3754.47 |
45053.62 |
|
8C16G |
180.48 |
7.52 |
4917.50 |
59010.00 |
|
8C32G |
187.20 |
7.80 |
5100.49 |
61205.91 |
|
10C24G |
202.14 |
8.42 |
5507.60 |
66091.20 |
|
10C48G |
226.39 |
9.43 |
6168.51 |
74022.14 |
|
16C32G |
234.62 |
9.78 |
6392.75 |
76713.00 |
|
16C64G |
255.68 |
10.65 |
6966.56 |
83598.74 |
|
32C128G |
511.37 |
21.31 |
13933.12 |
167197.49 |
|
性能型磁盘1G |
0.02 |
0.0007 |
0.41 |
4.90 |
|
硬盘(SSD)1G |
0.05 |
0.0020 |
1.16 |
13.92 |
续费说明
为保证业务的正常运行,创建时系统默认为您开启自动续约。开启自动续约后,下个计费周期(自然月)起始时将自动按当前设定的计费方式与规格自动完成续约。续约时需扣除相应费用,请确保账户余额充足。
关闭自动续约后,到期时Kafka集群将会被删除,数据无法找回






 扫描上方二维码
扫描上方二维码